[hwp + python 업무자동화] 졸업 사정안 자동화프로그램 #4
필드값 입력을 위한 PutFieldText
< 목차 >
1. field_list의 생성
2. 필드 범위 분할
3. 필드 리스트의 재정렬
4. hwp.PutFieldText(field, value)
한글문서 자동화를 위해서는 원하는 누름틀과 셀의 field에 값을 선택적으로 입력하거나 업데이트 해야한다.
데이터를 필드에 입력할 때 문서의 첫 번째 필드부터 순차적으로 모든 필드에 값을 입력할 수도 있지만, 조건에 따라 일부분만 입력하거나, 기존에 입력한 값을 수정할 수도 있기 때문에 "내가 원하는 필드에 값을 어떻게 입력할 것인가?"가 파이썬 초보자인 나에게 가장 큰 난관이었다.
경험치가 많지 않기 때문에 다양한 방안을 떠올릴 수 없지만 최종적으로 내린 결론은 한글 문서의 모든 필드를 List로 생성하고, 한글필드에 입력할 값도 List로 생성한다. 이 두 리스트를 순차적으로 매칭하여 필드를 업데이트를 하면 된다.
만약 모든 필드가 아닌 일부분만 입력한다면 값을 입력할 필드와 값을 List를 생성하면 되기 때문에 다양한 조건에 따라서 입력방식을 조절하기가 쉽다.
필드 List 생성
#문서의 처음으로 이동
hwp.Run("MoveDocBegin")
#누름틀 리스트 확인
field_list = [i for i in hwp.GetFieldList().split("\x02")]
hwp.Run("MoveDocBegin")
먼저 한글 문서의 캐럿(커서)의 위치를 문서의 처음으로 이동시킨다. 문서의 처음으로 이동하지 않으면 마지막으로 저장된 위치에서부터 작업이 시작되기 때문에 자동화 전에 커서의 위치를 이동하는 것이다.
field_list = [i for i in hwp.GetFieldList().split("\x02")]
GetFieldList는 한글문서의 필드리스트를 가져오는 컨트롤이다.
split는 문자열을 구분자를 통해 분할하여 문자열을 돌려주는 함수이다. 문자열.split(구분자, 최대분할횟수)
위의 코드에서 구분자로 사용할 "\x02"를 기준으로 필드리스트의 문자열을 분할하고, 리스트로 반환한다.
구분자로 "\x02"로 사용하는 것은 GetFieldlist로 필드리스트는 “필드이름#1\x2필드이름#2\x2...필드이름#n"의 형태로 반환한다. 그렇기 때문에 for반복문으로 split함수를 통해 원하는 필드 이름만 분할하여 field_list를 생성한다.
필드 List 분할
# 필드 범위 분할
result_table = {}
tables = ['inout', 'all', 'fall']
for table in tables:
if table == 'all' or 'inout':
filtered_table = [item for item in field_list if item.startswith(table) and not item.endswith('1')]
elif table == 'fall':
filtered_table = [item for item in field_list if item.startswith(table) and not (item.endswith('1') or item.endswith('2'))]
result_table[table] = filtered_table
result_table = { }
먼저 빈 딕셔너리를 생성한다. result_table 딕셔너리에는 분할된 필드리스트를 List의 형태로 입력할 것이다.
tables = ['inout', 'all', 'fall']
필드리스트의 분할은 필드이름을 기준으로 한다. 필드이름을 생성하는 과정에서 자료의 속성에 따라서 필드이름을 "데이터 그룹명_A1"의 형태로 생성하였다. 필드이름 앞에 붙은 데이터 그룹명을 활용하여 전체 필드를 분할할 것이다.
그렇기 때문에 자동화를 적용할 사정인원정보표의 그룹명을 inout으로, 3개년 개근대상자 표의 그룹명을 all으로, 3개년 정근대상자 표의 그룹명을 fall으로 부여하였다.
그룹명에 해당하는 값을 tables 리스트에 할당한다.
for table in tables:
tables 리스트에 포함된 inout, all, fall를 하나씩 순환하면서 반복문을 실행한다.
if table == 'all' or 'inout':
일반적으로 한글파일의 표에서는 첫 행은 제목이 입력되는 경우가 많다. 표의 모든 셀에 정보를 입력하는 것이 아니기 때문에 제목셀과 같이 불필요한 셀을 필터링하여 필드리스트를 생성해야 한다.
다음 그림에서 음영처리된 부분은 all과 inout 표에서 첫번째 행은 제목행로 불필요한 값이기 때문에 이 행을 제외하고 필터링하여 리스트를 생성하고자 한다.

filtered_table = [item for item in field_list if item.startswith(table) and not item.endswith('1')]
이 코드는 조금 복잡해 보이지만 리스트 컴프리헨션을 통해 불필요한 값을 필터링하고 리스트를 생성한다. 리스트 컴프리헨션은 field_list 의 각 항목을 반복한다.
item.startswith(table) 은 현재 항목이 table 변수에 저장된 문자열(inout 또는 all)로 시작하는지 확인하고
not item.endswith('1') 은 현재 항목이 1로 끝나지 않는지 확인한다. 이때 1로 끝나지 않는지 확인하는 것은 제목행의 필드는 모두 inout_A1, inout_B1과 같이 1번행에 해당하기 때문이다.
두 조건(item.startswith(table) 및 not item.endswith('1'))이 동시에 참인 경우 해당 항목이 filtered_table에 포함된다.
간단하게 말하면, filtered_table에는 field_list의 항목 중 table의 값으로 시작하고 '1'로 끝나지 않는 항목만 포함하는 것이다.
elif table == 'fall':
filtered_table = [item for item in field_list if item.startswith(table) and not (item.endswith('1') or item.endswith('2'))]
정근 대상자 테이블의 경우 아래 그림에서처럼 행이 분할되어 있는 것을 볼 수 있다. 그렇기 때문에 1행과 2행은 제목열에 해당하기 때문에 이 두 행을 제외시킨다.

result_table[table] = filtered_table
필터링된 테이블은 result_table에 리스트의 형태로 저장이 된다.
분할된 필드 List 재정렬
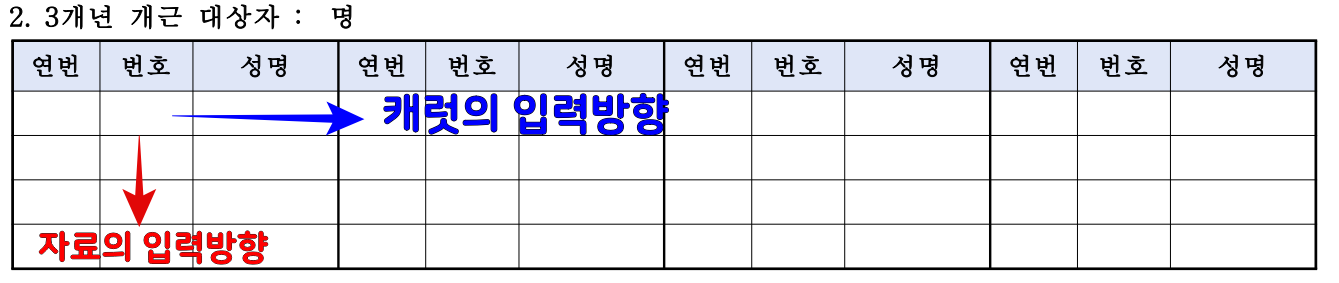
필드 리스트를 재정렬 하는 것은 캐럿(커서)의 이동방향 때문에 필요하다.
필드 리스트를 생성할 때 캐럿의 이동방향은 A1셀부터 횡축으로 움직이고, 1행의 마지막 셀이 오면 B1셀로 이동하는 형태이다.
하지만 아래처럼 데이터를 입력하는 방향은 세로축이기 때문에 필드리스트의 정렬방향을 자료의 입력방향과 일치하도록 재정렬하는 과정이 필요하다. 입력한 값은 순차적으로 정렬되어 있기 때문에 필드와 입력할 값을 1 대 1 로 대응하여 입력할 수 있다.
#사용자 정렬 함수
def custom_sort(item):
# 알파벳에 대응하는 숫자 정의
alphabet_order = {'A': 1, 'B': 5, 'C': 9, 'D': 2, 'E': 6, 'F': 10, 'G': 3, 'H': 7, 'I': 11, 'J': 4, 'K':8, 'L':12}
# 정렬을 위한 키 생성
match = re.match(r'all_([a-zA-Z]+)([0-9]+)', item)
return (alphabet_order[match.group(1)], int(match.group(2)))
sorted_data_list = sorted(result_table['all'], key=custom_sort)
#입력할 항목별로 sort_data_list를 분할 : 연번/번호/성명
split_all_field = {'연번': [], '번호': [], '성명': []}
for item in sorted_data_list:
match = re.match(r'all_([A-L])([2-5])', item)
if match:
group = match.group(1)
if group in ['A', 'D', 'G', 'J']:
split_all_field['연번'].append(item)
elif group in ['B', 'E', 'H', 'K']:
split_all_field['번호'].append(item)
elif group in ['C', 'F', 'I', 'L']:
split_all_field['성명'].append(item)
필드리스트를 재정렬하기 위해 사용자 정렬 함수를 생성하였다. 표마다 자료가 입력되는 방향과 범위가 조금씩 다르기 때문에 표마다 개별적으로 조건을 지정해야 한다. 이 함수는 3년 개근 대상자 표를 기준으로 정렬기준을 설정하였다.
alphabet_order = {'A': 1, 'B': 5, 'C': 9, 'D': 2, 'E': 6, 'F': 10, 'G': 3, 'H': 7, 'I': 11, 'J': 4, 'K':8, 'L':12}
사용자 정렬 함수는 일단 셀주소의 알파벳에 대응하는 숫자를 정의한다. 이 대응되는 숫자자 정렬기준이 되기 때문에 입력할 자료의 속성을 고려하여 대응 숫자를 정의해야 한다.
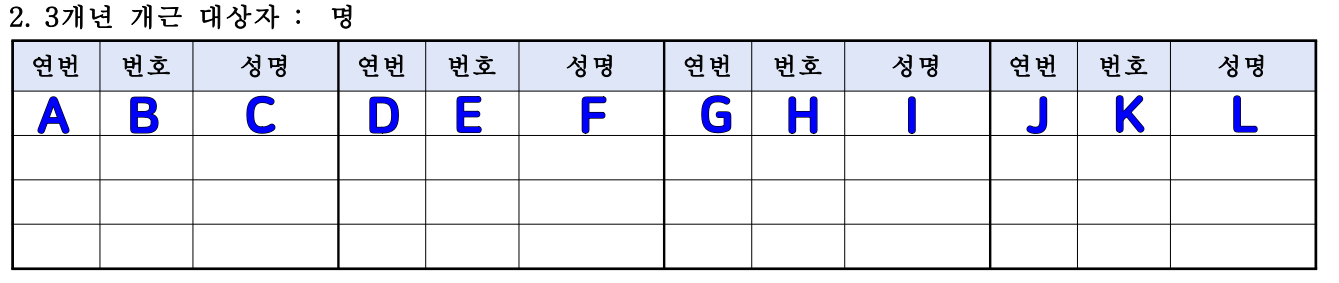
위의 그림을 보면 A열, D열, G열, J열의 순서대로 연번이 증가할 것이기 때문에 A열이 1, D열이 2, G열이 3, J열이 4가 되는 것이다.
match = re.match(r'all_([a-zA-Z]+)([0-9]+)', item)
return (alphabet_order[match.group(1)], int(match.group(2)))
# match.group(1)은 문자열의 알파벳 부분을 나타냅니다.
# match.group(1)에 해당하는 알파벳의 순서를 가져오고, 이를 기준으로 정렬합니다.
# match.group(2)는 문자열의 숫자 부분을 나타냅니다.
# int(match.group(2))를 통해 숫자를 정수로 변환하여 기준으로 정렬합니다.
이 함수는 주어진 문자열 item이 패턴 all_([a-zA-Z]+)([0-9]+)과 일치하는지 확인하고, 그룹화된 알파벳 부분과 숫자 부분을 사용하여 정렬을 위한 키를 생성합니다. 반환된 튜플은 알파벳 부분의 순서와 숫자 부분을 기준으로 정렬에 사용됩니다.
다음 글에서는 실제로 PutFieldtext를 통해 필드에 값을 입력하는 기능을 구현하겠다.
'교무업무자동화' 카테고리의 다른 글
| [구글폼 자동화] 학년초 학생 기초생활조사1 #한글양식 (2) | 2024.01.25 |
|---|---|
| [구글폼 자동화] 학년초 학생 기초상담카드 #기획 (0) | 2024.01.19 |
| [hwp + python 업무자동화] 졸업사정안 자동화 #4 pandas (0) | 2023.12.19 |
| [hwp + python 업무자동화] 졸업사정안 자동화 #3 KeyIndecator의 활용 (2) | 2023.12.15 |
| [hwp + python 업무자동화] 졸업사정안 자동화 #2 Field컨트롤 (1) | 2023.12.07 |